Taking previous work from Part 1, this will continue to cleansing and transforming the data which include numpy libraries.
Setting up indicators with Panda
import google.datalab.bigquery as bq
import numpy as np
import pandas as pd
bq_vm = bq.Query('SELECT * FROM EDA.vpx_vm')
output_opt = bq.QueryOutput.table(use_cache=False)
##Print result set
raw = bq_vm.execute(output_options=output_opt).result()
source_df = raw.to_dataframe()
# getting vm_id column as indicator variable with panda
source_df = pd.concat([source_df, pd.get_dummies(source_df['vm_id'],prefix='Column_vm_id')],axis=1)
source_df = pd.concat([source_df, pd.get_dummies(source_df['updated_time'],prefix='Column_updated_time')],axis=1)
source_df.head(9)

Describe() and Corr()
import google.datalab.bigquery as bq
import numpy as np
import pandas as pd
#Prerequisite - Load or create the table to BigQuery Dataset first.
bq_vm = bq.Query('SELECT * FROM EDA.vpx_vm')
output_opt = bq.QueryOutput.table(use_cache=False)
##Print result set
raw = bq_vm.execute(output_options=output_opt).result()
source_df = raw.to_dataframe()
# getting vm_id column as indicator variable
source_df = pd.concat([source_df, pd.get_dummies(source_df['vm_id'],prefix='Column_vm_id')],axis=1)
source_df = pd.concat([source_df, pd.get_dummies(source_df['updated_time'],prefix='Column_updated_time')],axis=1)
#source_df.head(9)
#The describe will take longer.
#It comes up with count, mean, standard deviation, minimum, percentiles and max.
#source_df.describe()
#this will take a long time.
source_df.corr()['ds_id']

Saving the results in the bucket - Cloud Storage
import google.datalab.bigquery as bq
import numpy as np
import pandas as pd
from StringIO import StringIO
#Prerequisite - Load or create the table to BigQuery Dataset first.
bq_vm = bq.Query('SELECT * FROM EDA.vpx_vm')
output_opt = bq.QueryOutput.table(use_cache=False)
##Print result set
raw = bq_vm.execute(output_options=output_opt).result()
source_df = raw.to_dataframe()
# getting vm_id column as indicator variable
source_df = pd.concat([source_df, pd.get_dummies(source_df['vm_id'],prefix='Column_vm_id')],axis=1)
source_df = pd.concat([source_df, pd.get_dummies(source_df['updated_time'],prefix='Column_updated_time')],axis=1)
#source_df.head(9)
#The describe will take longer.
#It comes up with count, mean, standard deviation, minimum, percentiles and max.
#source_df.describe()
#this will take a long time.
#source_df.corr()['ds_id']
#saving the results to Cloud Storage
csvObj=StringIO()
source_df.corr()['ds_id'].to_csv(csvObj)
Creating csv file in GCS Bucket
%%gcs write --variable csvObj --object 'gs://datalab-project-1-239921/storing_correlation_data.csv'
The gcs write will create the new csv file in the GCS Bucket.

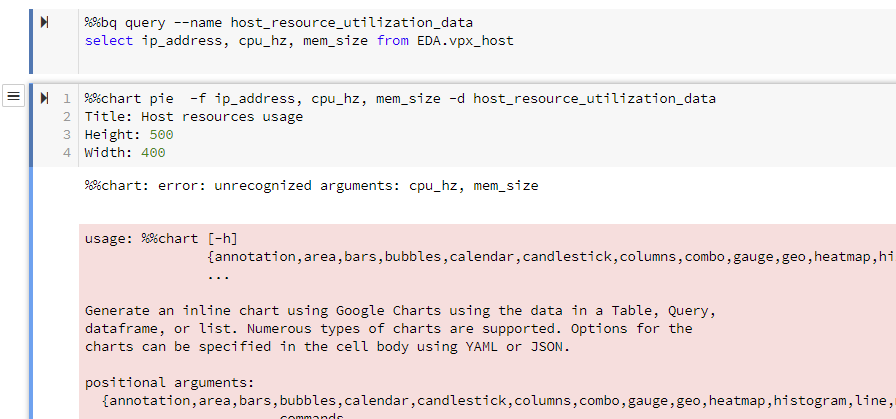
I am lacking meaningful data to play with especially in the Correlation and Std Deviation parts. Though, the GCS APIs worked.